AIの問題点:すべての企業が直面するAI導入の避けられない問題点
AIを既存のシステムや製品に統合することは、確かにビジネス上のメリットを大量にもたらします。しかし、あなたはまだこれらのAIの問題を考慮したことがありますか?


データの質はビジネスの成長に重要な影響を与える。ビッグデータと手作業によるデータ収集方法の助けもあり、データ資産は収集データソースと種類の両面でますます多様化し、肥沃になっている。人々の生活や世界の仕組みが常に並行して変化しているため、データは数分、数秒で作成される。
すべてのコインには表と裏がある。今日の膨大なデータ収集において、すべてのデータ記録は質の高いデータなのだろうか?残念ながら、答えはノーだ。エントロピー的なシステムと同じように、データには無効なデータ、冗長なデータ、重複したデータなど、データ品質の問題がつきまとう。数え上げればきりがない。正確なデータ」は当初は存在しないが、データ品質が悪いと、年間平均1500万ドルの財務コストが発生する。データ品質を過小評価することは、意思決定プロセスやビジネスの競争力に悪影響を及ぼす。データ品質に関する最も一般的な問題トップ8と、それに対する専門家の解決策をご覧ください。

データの質が低いと、業務効率が低下することは周知の事実である。しかし、データ品質の問題は具体的にどのようにビジネスに影響するのだろうか。データ品質の問題には多くの種類がある。データケースごとに悪影響が異なるのもそのためです。以下に、すべてのデータチームがデータ管理の失敗によって被る、データの衰退という一般的な結果をいくつか挙げる。

収集されたデータは決して完璧ではありません。どんなに高度なデータ品質ツールや自動化ソリューションを使用しても、テクノロジーだけで企業のデータ品質問題を徹底的に解決することはできない。データパイプラインの中で、企業は少なくとも一度は以下に挙げるようなデータ品質の問題に遭遇しているはずだ。データに関する問題のトップ8を確認し、専門家がデータ品質の問題をどのように解決しているかを見てみよう。
重複データとは、同じデータレコードや同じ情報を複数のバリエーションで保存している特定のシステムやデータベースを指します。データ重複の一般的な原因には、データの再インポートが複数回行われる、データ統合プロセスでデータが適切にデカップリングされない、複数のデータソースからデータを取得する、データのサイロ化などがあります。
例えば、オークションサイトにオークション商品が2度出品された場合、潜在的な購入者とウェブサイトの信頼性の両方に悪影響を及ぼす可能性があります。レコードが重複している場合、この問題はストレージスペースの浪費につながり、分析結果が歪む可能性が高くなる。
この問題に対する専門家の解決策を紹介しよう:
多くの組織は、すべての顧客データを取得し、保存することが、ある時点で自社に利益をもたらすと考えている。しかし、必ずしもそうではない。データ量は膨大で、すべてがすぐに役立つわけではないため、企業は代わりに無関係なデータの質の問題に直面する可能性がある。無関係なデータが長期間保存されると、すぐに古くなり、ITインフラに負担をかけ、データチームの管理時間を消費しながら、その価値を失ってしまう。
例えば、役職や配偶者の有無のような関連データは、企業の製品販売動向に関する貴重な洞察を提供しない。そうでなければ、重要なデータ要素を分析する過程で邪魔になる。
この問題に対する専門家の解決策を紹介しよう:
非構造化データは、多くの要因からデータ品質の問題とみなされることがある。非構造化データとは、テキスト、音声、画像など、特定のデータ構造やモデルに整理されないあらゆるタイプのデータを指すため、企業がデータを保存し、分析することは困難です。
他の種類の生情報と同様に、非構造化データは複数のソースから提供され、重複、無関係、またはエラー情報を含む可能性がある。非構造化データを意味のある洞察に抽出するには、専門的なツールと統合プロセスが必要なため、容易ではない。これはもはやコストの問題ではなく、専門知識とデータアナリストの雇用の両方の問題である。
そのような潜在的なデータを処理するのに必要な能力やリソースが十分でない場合、企業は非構造化データよりも構造化データを優先することができる。しかし、非構造化データ資産をデータベースから削除する前に、投資コストと隠れた利益の差額を慎重に計算する必要がある。
この問題に対する専門家の解決策を紹介しよう:
データのダウンタイムとは、データが準備できない、あるいは利用できない、アクセスできない期間を指す。データのダウンタイムが発生すると、組織や顧客は必要な情報に接続できなくなる。これは、不注意にもこれらのオーディエンスのニーズを混乱させ、分析結果の低下や顧客からの苦情につながる。
データのダウンタイムを引き起こす一般的な要因には、スキーマの予期せぬ変更、移行の問題、技術的な問題、ネットワークやサーバーの障害など、管理システムの状態によって異なるものがある。データをシステムに戻し、データのダウンタイムを回避するために、データエンジニアはデータパイプラインの更新と品質保証に時間を費やす必要がある。データの維持と保存に時間がかかればかかるほど、ビジネスが費やす潜在的なリソースは増え、顧客の信頼に悪影響を及ぼす。
この問題に対する専門家の解決策を紹介しよう:
データは多くの異なる情報源から得られるため、情報源間の同じ情報の不一致は避けられない。この状態を総称して “不整合データ “と呼ぶ。データの不整合は、人為的なミスによる手作業でのデータ入力ミス、非効率的なデータ管理方法など、様々な要因によって発生する。その中でも、単位や言語の違いという思いもよらない理由がある。
日付の表し方は、それに近い例である。そのソースのフォーマット要件に応じて、日付は2023年4月14日、14/04/2023、04-14-2023など、さまざまな方法で表現することができます。この場合、間違った日付形式はありません。しかし、これはデータの品質に深刻な影響を与えます。
原因や形式にかかわらず、一貫性のないデータはデータの健全性を低下させ、あらゆる業務を混乱させ、データ本来の価値を破壊する。
この問題に対する専門家の解決策を紹介しよう:
不正確なデータとは、その品質と信頼性に影響する誤りを含むデータのことである。かなり広範な概念であるため、不完全、時代遅れ、一貫性がない、誤字脱字、欠落や不正確な値など、その他のデータ品質上の問題も不正確なデータとみなされる。
実用的な知見を得るためには、収集されたデータの精度が高く、現実の状況を反映していることが必要かつ十分である。しかし、データ入力プロセスにおける人為的ミスやデータのドリフトなど、多くの外部要因や内部要因の影響を受け、情報はデータ入力時のような本来の正確性を保つことはできない。不正確なデータは、企業が誤った決定を下し、提供された情報で顧客を失望させる原因となる。
例えば、CRMデータベース内の顧客情報に関する誤ったデータは、マーケティングキャンペーンの不調、収益の損失、顧客の不満につながる。
この問題に対する専門家の解決策を紹介しよう:
企業は業務効率化のためにデータを抽出・分析する。しかし、膨大な量のデータが存在する今日、ほとんどの企業はその一部しか利用していない。データサイロに残っている未使用または欠落したデータは、隠しデータと呼ばれる。より具体的には、隠されたデータは、価値があるにもかかわらず使用されず、他のファイルや文書の中に保存されていたり、メタデータのような顧客には見えない情報であったりする。
例えば、ある企業の営業チームは顧客に関するデータを持っているが、カスタマーサービスチームは持っていない。必要な情報を共有しなければ、企業はより正確で完全な顧客プロファイルを作成する機会を失うかもしれない。
隠されたデータは利用されるか、削除されるべきである。このようなデータ品質の問題が存在することは、リソースを浪費するだけでなく、隠しデータがデータセット内の機密データであれば、プライバシー監視やコンプライアンス違反につながる可能性さえある。
この問題に対する専門家の解決策を紹介しよう:
収集されたデータはすぐに陳腐化し、人間生活の発展と近代化によってデータの衰退を招くことは避けられない。現状ではもはや正確でも適切でもない情報はすべて、古くなったデータとみなされる。名前、住所、連絡先など、顧客に関する情報は、会社のサービスやプロモーションについて相談する機会を逃さないよう、常に更新される必要がある良い例である。
古いデータの問題は、正確さへの懸念だけでなく、企業のデータベース管理システムへの投資や関心の遅れや欠如を反映している。古いデータがもたらす結果は、誤った洞察、不十分な意思決定、誤解を招く結果にまで及ぶ可能性がある。
この問題に対する専門家の解決策を紹介しよう:
データ品質の問題は、その種類に関わらず、業務に悪影響を及ぼします。オリエント・ソフトウェアは、この記事を通じて、そのような問題を制限し、あるいは排除するための貴重な専門家によるソリューションを提供します。しかし、人間はすべての組織のコア・バリューです。データ品質の問題を完全に解決するためには、企業の担当者の意識と専門的スキルを訓練し、向上させることに勝る解決策はありません。
AIを既存のシステムや製品に統合することは、確かにビジネス上のメリットを大量にもたらします。しかし、あなたはまだこれらのAIの問題を考慮したことがありますか?
教育における人工知能という言葉を聞いたことがあるだろうか?もしそうでないなら、AIが教育分野でどのような役割を果たし、どのように応用されているのか、その理由を探ってみましょう。
人工知能プロジェクトを始めるなら、この成功のためのAIプロジェクト設定ガイドが必要です。今すぐチェック
AI と並んで、機械学習 (ML) や深層学習 (DL) などの用語が登場し始めており、同じ意味で使用されることもあります。 これらの用語の違いと、各テクノロジーがビジネスに何をもたらすかを見てみましょう。
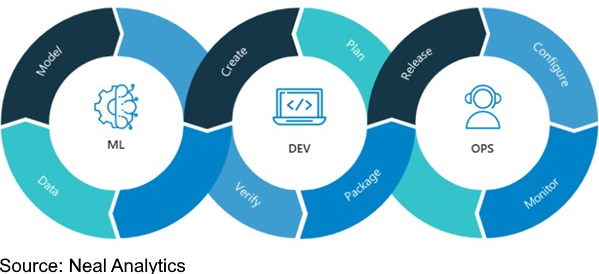
MLOpsとは、MLシステム開発(Dev)とMLシステム運用(Ops)の一体化を目指すMLエンジニアリングの文化であり、実践である。